How to persist Ktor logs
SERIES: Building a backend with Ktor
- Part 1: Structuring a Ktor project
- Part 2: How to persist Ktor logs
- Part 3: How to use an in-memory database for testing on Ktor
- Part 4: How to handle database migrations with Liquibase on Ktor
- Part 5 Generate API documentation from Swagger on Ktor
- Part 6: How to schedule jobs with Quartz on Ktor
- Part 7: Moving from mobile to backend development with Ktor
Logs are a vital part of software development. They can be used for debugging, to track specific events during the lifecycle of the product, or to discover unexpected events.
Usually, logs are printed in the system output, so they must be saved somewhere to be accessed and read sometime in the future. To achieve persistence it is possible to use a cloud service, like Datadog that receives, processes and maintains all the logs. Cherry on top, it also gives you monitoring and analysis tools right out of the box.
However, I think that, in the case of an MVP or an early-stage product, using such services can be overkill. It’s enough to persist the logs in the server and access them later.
In this post, I will show how to save on a file the logs produced by a Ktor backend. This post is part of a series of posts dedicated to Ktor where I cover all the topics that made me struggle during development and that was not easy to achieve out of the box. You can check out the other instances of the series in the index above or follow me on Twitter to keep up to date.
Setup logging on Ktor
When creating a new Ktor project, the wizard automatically adds the SLF4J library to handle logging.
During the initialization of the server, Ktor automatically creates an instance of the Logger and then it is possible to retrieve that instance in different ways. Instead, on business logic classes the Logger instance can be retrieved from the LoggerFactory.
val logger = LoggerFactory.getLogger(MyClass::class.java)
To avoid writing every time this long line, an helper method can be used:
inline fun <reified T> T.getLogger(): Logger {
return LoggerFactory.getLogger(T::class.java)
}
class MyClass {
private val logger = getLogger()
fun main() {
logger.info("Hello World")
}
}
Logger Customization
The Logger can be customized with an xml file named logback.xml. On project creation, a default logback file is created and placed in the application resources directory.
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{YYYY-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="trace">
<appender-ref ref="STDOUT"/>
</root>
<logger name="org.eclipse.jetty" level="INFO"/>
<logger name="io.netty" level="INFO"/>
</configuration>
The file contains three different blocks of configurations (this division is just visual and conceptual, of course, the order of the different entries can be changed and mixed).
In the first block, the Appenders are defined. An Appender is responsible to place the log messages in a specific destination.
<configuration>
...
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{YYYY-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
...
</configuration>
In this case, the ConsoleAppender will send the log messages in the Console, i.e. in the Standard Output. Inside the Appender customization, it is also possible to specify the format of the message and add useful information like the timestamp, the logger, the thread, etc.
The second block defines for each appender, the level of logging. The levels are 5: ERROR, WARN, INFO, DEBUG, TRACE, and the chosen one includes also the previous. For example, if you choose the TRACE level, all the messages will be sent, and if you choose the INFO level, only the messages with level INFO, WARN, and ERROR will be sent.
<configuration>
...
<root level="trace">
<appender-ref ref="STDOUT"/>
</root>
...
</configuration>
In this case, since the appender has logging level TRACE, all the log messages will be sent to the Standard Output.
In the third level instead, it is possible to customize the level of a specific logger.
<configuration>
...
<logger name="org.eclipse.jetty" level="INFO"/>
<logger name="io.netty" level="INFO"/>
...
</configuration>
For example, the DEBUG level can be set for a specific class that is not stable yet.
<logger name="com.company.package.MyClass" level="DEBUG"/>
If necessary, it is also possible to change at the same time all the levels of the Logger:
val root = LoggerFactory.getLogger(org.slf4j.Logger.ROOT_LOGGER_NAME) as Logger
root.level = ch.qos.logback.classic.Level.TRACE
This is useful for example to customize the log level if the instance is running on a staging or production server.
Logging on file
As you can imagine, to save the log on a file it is necessary to change the Appender. There is FileAppender and RollingFileAppender and I’m going to use the latter.
As the name suggests, a RollingFileAppender, does not save the logs in the same file but it “rolls” on different files depending on time, file size, or a mix of the two. This is a smarter solution to choose because otherwise, the log file will be too heavy when used for several days over.
<configuration>
...
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_DEST}/ktor-chuck-norris-sample.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- daily rollover -->
<fileNamePattern>${LOG_DEST}/ktor-chuck-norris-sample.%d{yyyy-MM-dd}.log</fileNamePattern>
<!-- keep 90 days' worth of history capped at 3GB total size -->
<maxHistory>${LOG_MAX_HISTORY}</maxHistory>
<totalSizeCap>3GB</totalSizeCap>
</rollingPolicy>
<encoder>
<pattern>%d{YYYY-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
...
</configuration>
First of all, in the RollingFileAppender it is necessary to specify the file where the logs will be saved. To define the location I’ve used an environment variable, so in this way, I can switch locations when I’m running the backend on my local machine.
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
...
<file>${LOG_DEST}/ktor-chuck-norris-sample.log</file>
...
<appender>
The variable is then specified in the VM Options field of the running configuration on IntelliJ
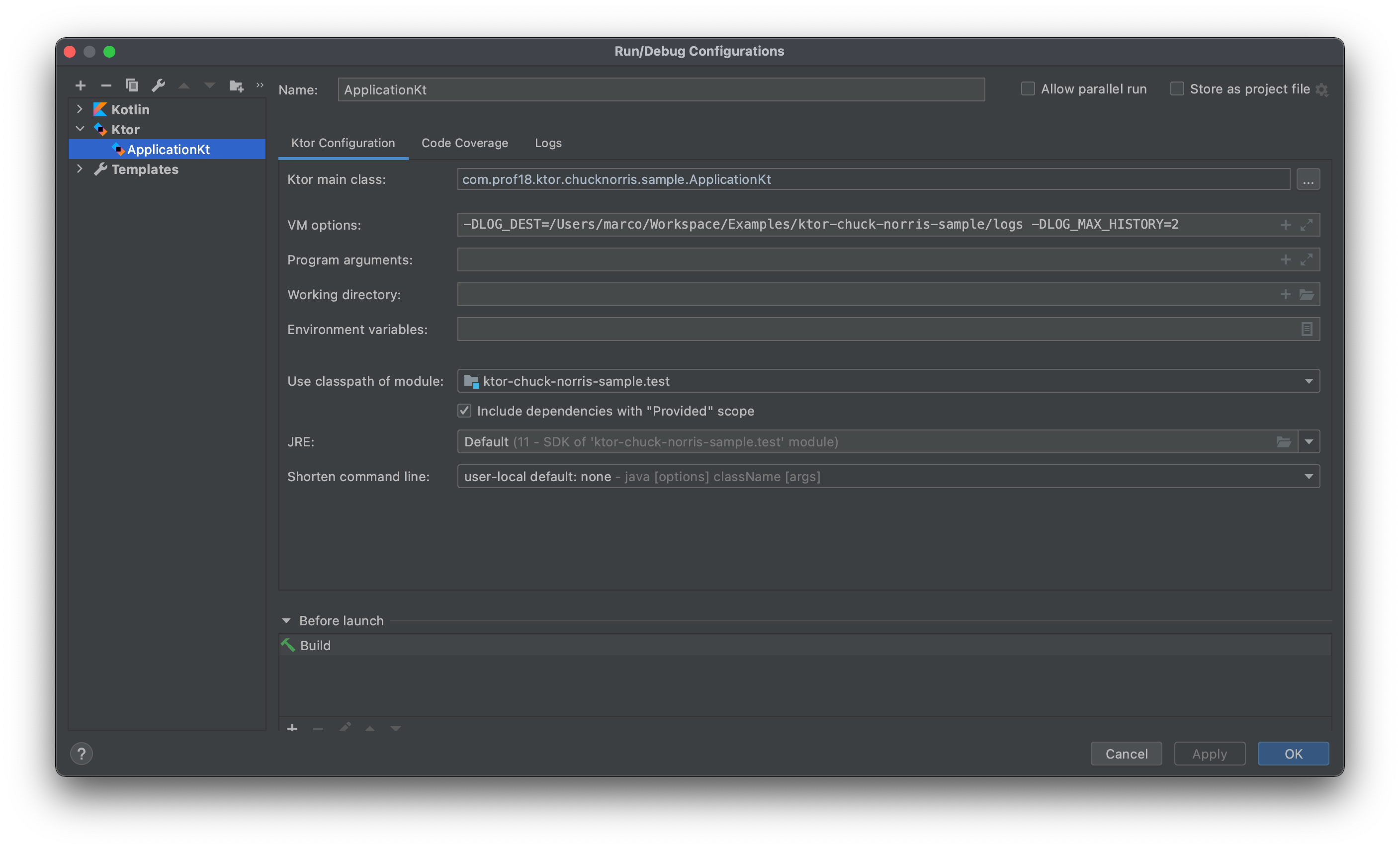
or in the command line when launching the backend.
java -DLOG_DEST=/rbe-data/logs ...
After the location, it is necessary to define a rolling policy. In this case, I will use a TimeBasedRollingPolicy, that changes every day the file where the logs are saved. Plus, it will append the date to the old files, to make them more recognizable.
├── logs
│ ├── ktor-chuck-norris-sample.2021-03-09.log
│ └── ktor-chuck-norris-sample.log
In the TimeBasedRollingPolicy, it is also possible to specify a limit on the number of days to persist and total max size. In this case, I’ve specified a maximum of 90 days and 3 GB size. So if there will be 3 GB of data on the 78th day, the logger will start automatically to drop the 1st day of log and so on.
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
...
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- daily rollover -->
<fileNamePattern>${LOG_DEST}/ktor-chuck-norris-sample.%d{yyyy-MM-dd}.log</fileNamePattern>
<!-- keep 90 days' worth of history capped at 3GB total size -->
<maxHistory>${LOG_MAX_HISTORY}</maxHistory>
<totalSizeCap>3GB</totalSizeCap>
</rollingPolicy>
...
</appender>
As for the location, I’ve used an environmental variable for the days, so in this way, I can set only one day of logs when I run the backend on my local machine.
java -DLOG_DEST=/rbe-data/logs -DLOG_MAX_HISTORY=90...
And as reference, here’s the entire logback file that I’ve described:
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{YYYY-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_DEST}/ktor-chuck-norris-sample.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- daily rollover -->
<fileNamePattern>${LOG_DEST}/ktor-chuck-norris-sample.%d{yyyy-MM-dd}.log</fileNamePattern>
<!-- keep 90 days' worth of history capped at 3GB total size -->
<maxHistory>${LOG_MAX_HISTORY}</maxHistory>
<totalSizeCap>3GB</totalSizeCap>
</rollingPolicy>
<encoder>
<pattern>%d{YYYY-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="info">
<appender-ref ref="STDOUT"/>
<appender-ref ref="FILE"/>
</root>
<logger name="org.eclipse.jetty" level="INFO"/>
<logger name="io.netty" level="INFO"/>
</configuration>
Logging during tests
While running tests is not necessary to save logs on file (at least in my case). To customize logging during testing, it is necessary to specify a logback-test.xml inside the test/resources directory.
In my case, I just wanted a simple ConsoleAppender.
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{YYYY-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="info">
<appender-ref ref="STDOUT"/>
</root>
<logger name="org.eclipse.jetty" level="INFO"/>
<logger name="io.netty" level="INFO"/>
<logger name="Exposed" level="INFO"/>
<logger name="ktor.test" level="INFO"/>
</configuration>
Conclusions
And that’s it for today. You can find the code mentioned in the article on GitHub.
In the next episodes, I’ll cover in-memory database and migrations. You can follow me on Twitter to know when I’ll publish the next episode.